Cloudflare (CF) recently expanded their offerings within the Workers AI product. Not only are there more model options but token thresholds have been raised. In order to access these larger token tiers you need to use response streaming done via Server-Sent Events (SSE). In a nutshell, SEE is simply a one-way version of WebSockets. You make a request to an HTTP resource and the host responds with data chunks that arrive through a keep-alive connection.
This is a great way to improve end-user UX as you can display the generated tokens from an LLM or other AI model without having to wait for the entire sequence to finish. It also allows Cloudflare to further granularize any inference task requested by a CF Worker. A real win-win in theory!
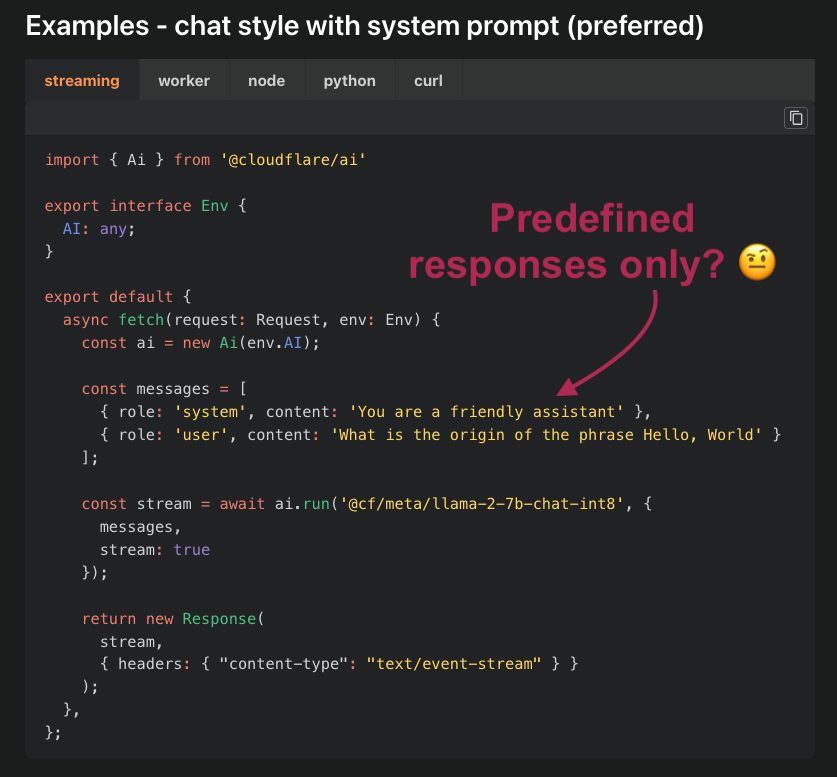
The Cloudflare docs are a nice starting point but fall short as they miss a crucial use case. What should the code look like when making a POST request with JSON content to feed to the AI model? Typical JS code to use SSE guides you to use EventSource constructs. But this only supports GET requests without a request body. Not useful if you’re planning on sending lots of text (e.g. a conversation log) to the AI model.
If you’re used to making fetch requests to a CF Workers AI backend but are unclear how to implement streaming, read on for a solution.
Backend
If you use Hono, stream with this:
import { Ai } from '@cloudflare/ai';
/* ... */
app.post('/chat/basic', async c => {
const ai = new Ai(c.env.AI);
const { messages } = await c.req.json();
const answer = await ai.run(
'@cf/meta/llama-2-7b-chat-fp16',
{
messages,
stream: true,
}
);
c.header('Content-Type', 'text/event-stream');
return c.stream(async stream => {
await stream.pipe(answer);
await stream.close();
});
});
or if you prefer with the bare Workers API:
import { Ai } from '@cloudflare/ai';
/* ... */
export default {
async fetch(request, env, ctx) {
if (request.method === "POST") {
const { messages } = await request.json();
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/meta/llama-2-7b-chat-int8', {
messages,
stream: true,
});
return new Response(stream, {
headers: { "content-type": "text/event-stream", },
});
}
},
};
Frontend
You will have to use a ReadableStream and a chunk handler to process the returned JSON chunks being streamed from the AI model. The initial fetch request can be made as normal with the substitution of application/json for text/event-stream:
const EVENTSTREAM_PREFIX = 'data: ';
const EVENTSTREAM_ENDED = '[DONE]';
const URL_AI_STREAM = 'https://...';
function requestAIStream(messages, chunkCallback) {
try {
const res = await fetch(URL_AI_STREAM, {
method: 'POST',
headers: { 'Content-Type': 'text/event-stream' },
body: JSON.stringify({ messages })
});
// Use a ReadableStream to handle the response
const reader = res.body
.pipeThrough(new TextDecoderStream())
.getReader();
while (true) {
// Handle each chunk
let { value, done } = await reader.read();
let totalMsg = '';
for (const l of value.split('\n')) {
if (!l) continue; // Skip empty lines
if (l.indexOf(EVENTSTREAM_PREFIX) >= 0) {
const msgChunk = l.substring(EVENTSTREAM_PREFIX.length);
if (msgChunk === EVENTSTREAM_ENDED) {
done = true;
} else {
const { response } = JSON.parse(msgChunk);
chunkCallback(response);
}
}
}
if (done) break;
}
// Close the stream from the client-side
reader.cancel();
} catch (e) {
console.trace(e);
}
}
Result
Exactly as you’d expect: the reply sequence tokens are streamed in and you can display them in real-time for a standard UI feedback